Architecture des applications (AA2)
- Architecture des applications (75 heures, coefficient 8)
- Architecture 3-tiers
- Architecture JEE
- Évolution des architectures
- Architectures orientées services
- Architectures micro-services
- API-Rest : Principes
- Les requêtes
- Les réponses
- API-Rest : Bonnes pratiques
- Les actions
- Les ressources
- Les réponses
- Les données
- Les relations
- Codage
- Filtrage
- Le problème des relations
- Utiliser JEE (API JAX-RS)
- Utiliser Spring
- Utiliser Spring Data Rest
- Authentification
- Génération d'un JWT
- Architectures JWT
- Utiliser un API Manager
- Services à haut-débit
- Programmation asynchrone
- Programmation Réactive
- Utiliser Spring Web-flux
- Un client réactif
- Le retour du un-pour-un avec les micro-threads
Architecture des applications (75 heures, coefficient 8)
Première partie (AA1) : Architecture Cloud des applications
- Responsable : Christophe Jullien (capgemini) et d'autres personnes
- Volume : 36 heures (CM / TP)
- Évaluation : à voir avec C. Jullien
- Compte pour 1/2 de la note finale
Deuxième partie (AA2) : Architecture JEE avancée (Spring-JPA / REST-API / JWT / VueJS / Reactive programming)
- Responsable : Jean-Luc Massat (jean-luc.massat@univ-amu.fr)
- Volume : 39 heures (3h de CM + 36 de TP)
- Évaluation : un projet à rendre par groupe de deux étudiants.
- Absence : Chaque absence non justifiée compte pour -1 point.
- Sujet : http://tinyurl.com/jlmassat2/arch-app
- Pré-requis : Java, JEE 1, SGBDR, HTTP/HTML/CSS/XML
- Compte pour 1/2 de la note finale
Architecture 3-tiers
Principe : Séparation entre
- la couche de gestion des données (données métier),
- la couche de présentation (logique applicative) et
- la couche métier (actions métier de traitement des données métier).
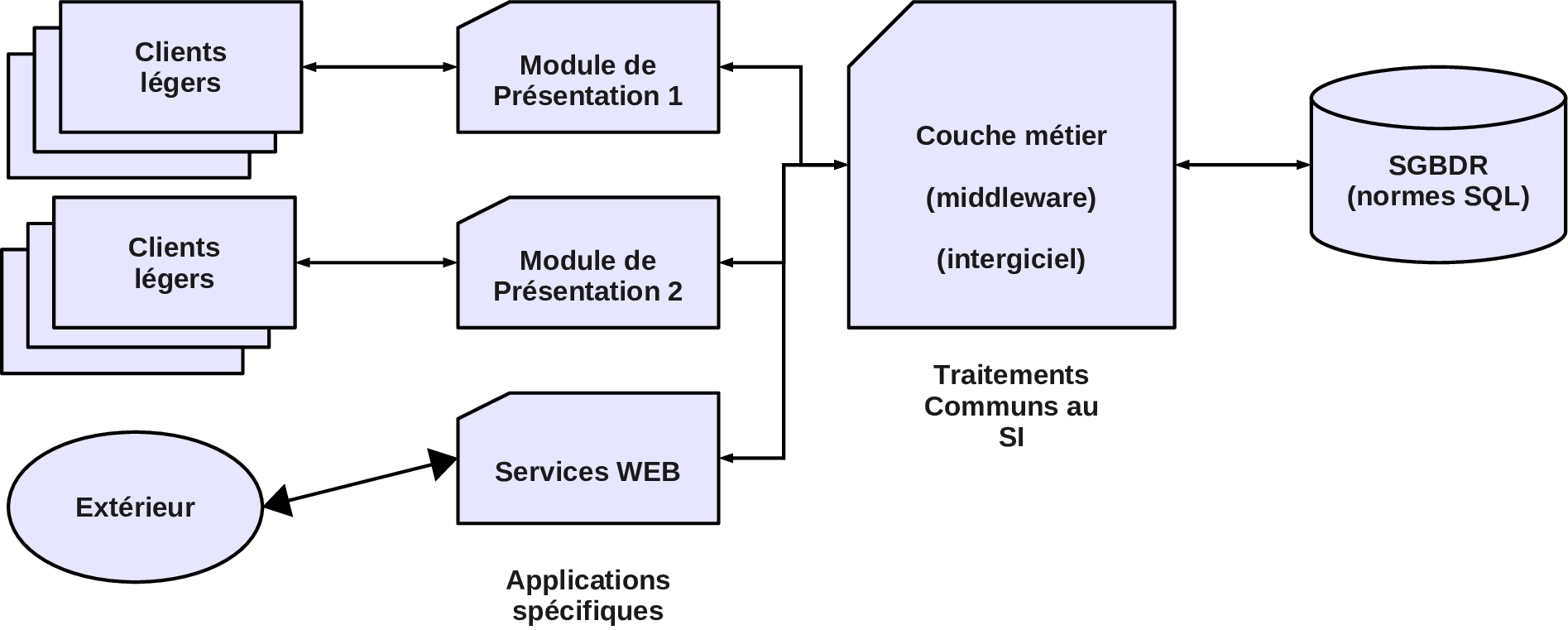
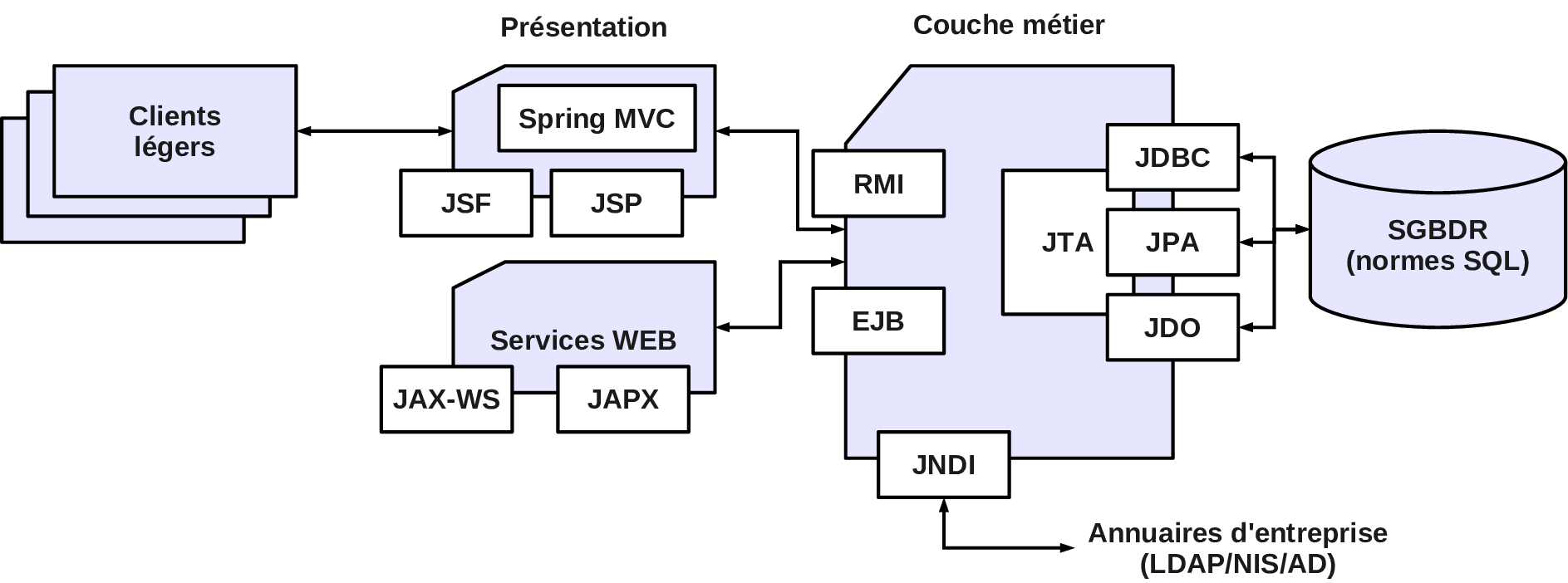
Architecture JEE
Java Enterprise Edition : JEE 8 (2017), Jakarta EE 8 (2019), JEE 9 (2020), JEE 9.1 (2021), JEE 10 (2022), JEE 11 (2025).
Cours de M1 : http://tinyurl.com/jlmassat2/jee-pour-M2
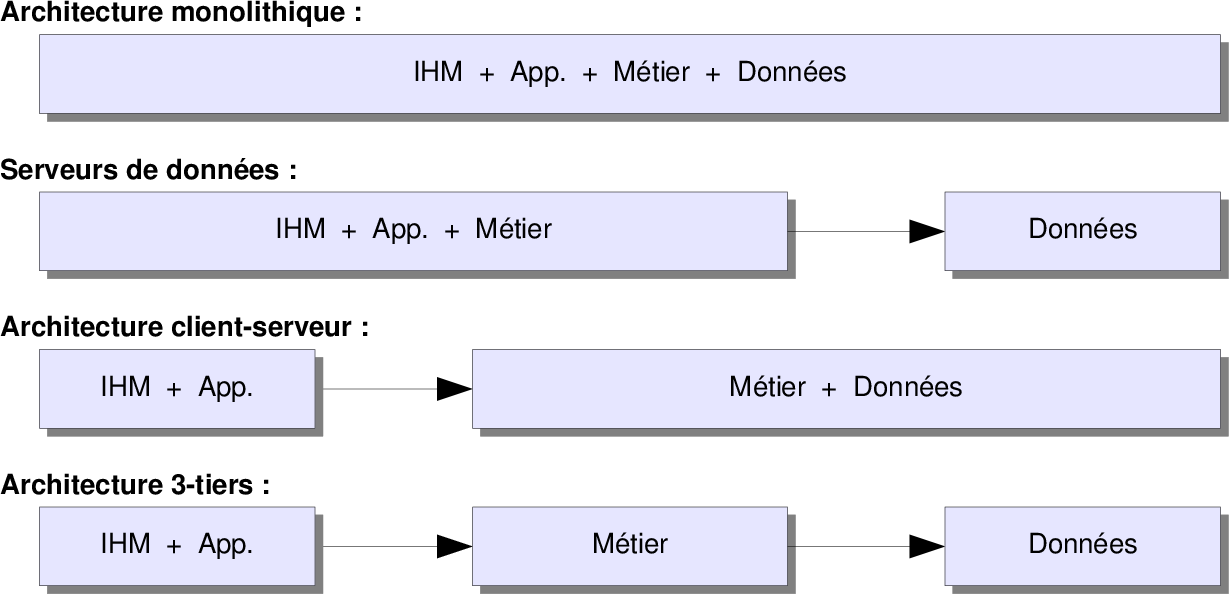
Évolution des architectures
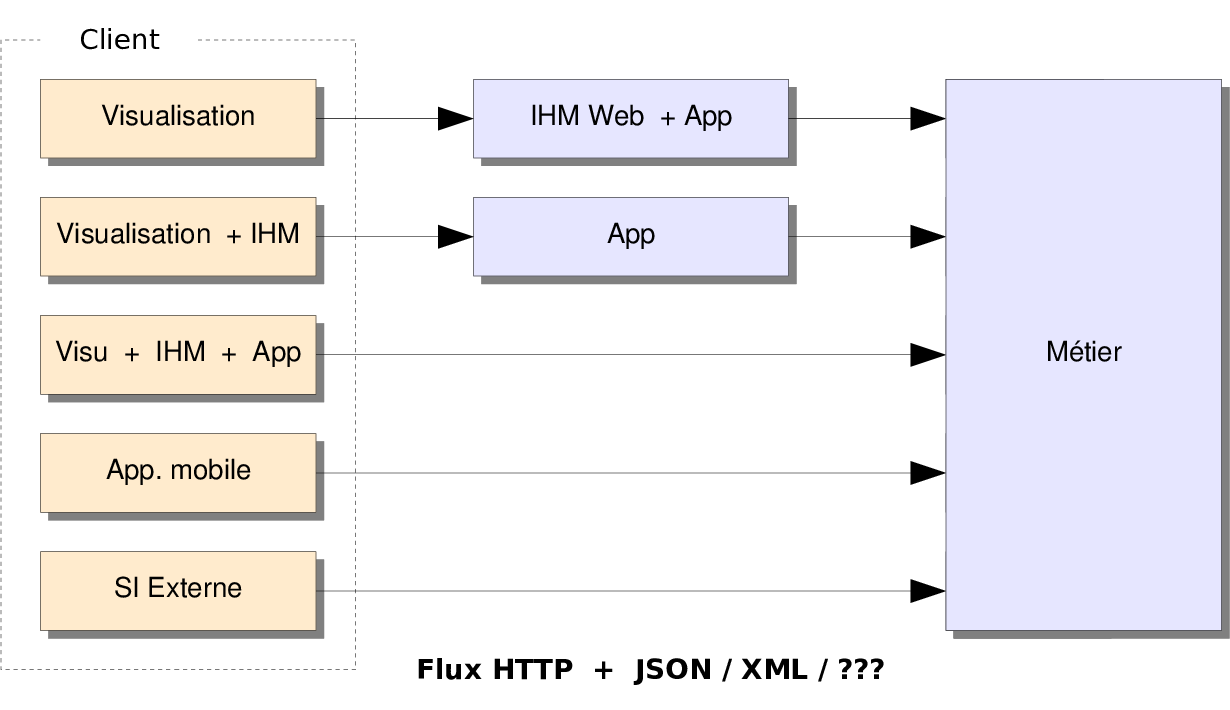
Architectures orientées services
Architectures micro-services
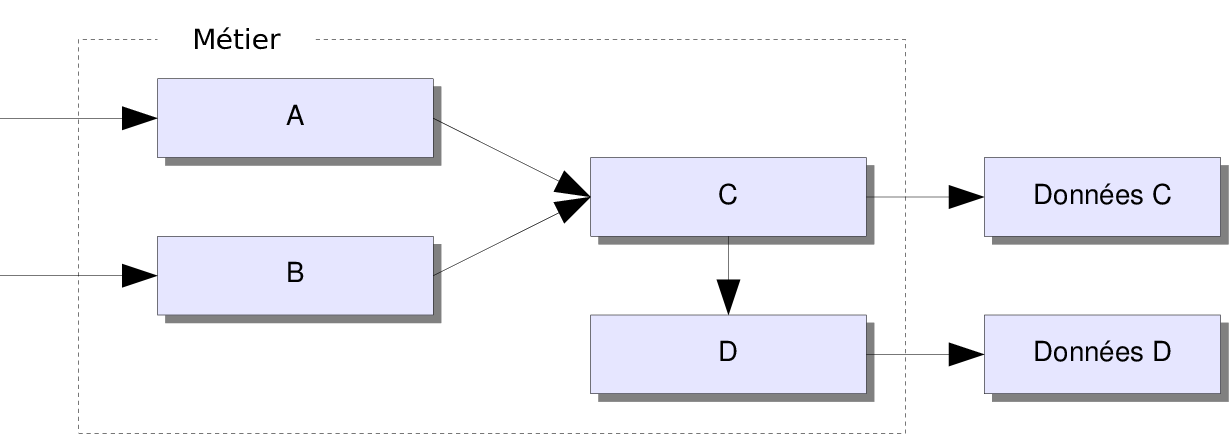
- Chaque micro-service possède une cohérence interne forte.
- Les micro-services sont déployés dans une machine virtuelle ou dans un conteneur via docker.
- L'ensemble est organisé via un système d'orchestration (kubernetes).
- La conception, la réalisation et le déploiement doit être rapide et souple.
API-Rest : Principes
Le protocole REST (REpresentational State Transfer), proposé en 2000, est une solution simple à la mise en place de (micro-)services WEB.
Caractéristiques :
- Indépendance des consommateurs et des producteurs.
- Protocole sans état.
- Les ressources manipulées sont identifiées par des noms (URI).
- Les actions sont limitées (en lien avec le protocole sous-jacent).
- Pas d'auto-description (contrairement à SOAP et WSDL).
- Le protocole ne nécessite pas d'encodage sophistiqué (pas d'enveloppe).
- Un cache est envisageable.
- L'utilisation de la bande passante est limitée.
Utilisation : basé la plupart du temps sur HTTP et JSON/XML, il est largement utilisé dans les applications WEB et mobiles.
Les requêtes
Les requêtes sont basées sur
- le transport via le protocole HTTP (TCP/IP),
- une action codée par la méthode HTTP (GET, POST, PUT, DELETE, ...),
- une ressource identifiée par l'URI,
- des données codées par
- des paramètres dans l'URI,
- une donnée XML/JSON placée dans le corps,
- des en-têtes.
GET /calculator/show HTTP/1.0 connection: keep-alive cache-control: no-cache 100
Les réponses
Les réponses sont basées sur
- le résultat HTTP (OK, Created, Accepted,...)
- les données codées par
- une donnée texte/XML/JSON placée dans le corps,
- des en-têtes.
HTTP/1.0 200 OK cache-control: no-cache, no-store, max-age=0, must-revalidate pragma: no-cache expires: 0 content-type: application/json date: Wed, 06 Oct 2020 16:01:43 GMT [100,200,300]
API-Rest : Bonnes pratiques
Les actions
Pour les actions, utilisez les méthodes HTTP :
- GET : Lire une information
- POST : Ajouter une information
- PUT : Modifier une information
- DELETE : Supprimer une information
- ...
Les ressources
Pour les ressources, utilisez des noms en anglais et au pluriel (pas de verbe) :
- GET /movies : Lire tous les films
- POST /comments : Ajouter un commentaire
Les réponses
Pour les réponses, utilisez le résultat HTTP :
- 200 OK : ressource trouvée
- 404 Not Found : ressource non trouvée
- 403 Forbidden : opération interdite
- 201 Created : ressource créée
- 204 No Content : ressource détruite
- ...
Les données
Pour identifier une donnée, utilisez les sous-ressources :
- GET /users/100 : Lire l'utilisateur identifié par 100
- PUT /movies/AZ401 : Modifier le film AZ401
- DELETE /comments/200 : Supprimer le commentaire 200
Les clefs primaires doivent être simples. Cela favorise la mise en place d'ID auto-générés et l'utilisation de clefs naturels n'est pas souhaitable.
Les relations
Pour gérer les relations, utilisez également les sous-ressources :
User --> OneToMany --> Post Post --> OneToMany --> Comment
- GET
/users/100/posts :
Lire les publications de l'utilisateur 100. - POST
/posts/200/comments/300 :
Ajouter le commentaire 300 à la publication 200. - DELETE
/posts/400/comments/500 :
Délier le commentaire 500 à la publication 400.
Codage
Utilisez de préférence un encodage UTF-8 et typez correctement le résultat de vos requêtes : application/json (ou XML).
Enrichissez vos réponses de liens vers les autres actions possibles (principe HATEOAS : Hypermedia As The Engine of Application State). Un exemple : la requete GET /users/100 va vous renvoyer
{
"name": "User 100",
"id": 100,
"_links" : {
"self": "http://localhost:8080/users/100",
"list": "http://localhost:8080/users"
"xxxx": "http://localhost:8080/users/100/xxxx"
}
}
Ce principe est très difficile à respecter à moins d'utiliser un outil automatique.
Filtrage
Prévoyez d'offrir des fonctions de filtrage, de tri et de pagination :
- GET /users?name=fred : lister les utilisateurs qui s'appellent « fred ».
- GET /users?sort=-name,+id : lister les utilisateurs triés de manière décroissante sur le nom et de manière croissante sur l'ID.
- GET /users?limit=10&offset=100 : lister au plus 10 utilisateurs à partir de la position 100.
Prévoyez un mécanisme de versionnage de votre API.
- GET /api/users : les utilisateurs (version par défaut).
- GET /api3/users : les utilisateurs dans la version 3.
- GET /api/users?version=4 : les utilisateurs dans la version 4.
Le problème des relations
Il est intéressant de gérer les relations de manière plus directe en utilisant des versions adaptées des entités (DTO : Data Transfert Object).
Données --> API Rest --> DTO --> Entité --> JPA --> SGBDR
Nous remplaçons (pour les publications) l'entité par l'objet DTO :
public class Post {
String title;
String description;
User user;
...
}
{ "title":"Un titre",
"description":"Un texte",
"user": { "name":"User1" } }
public class PostDTO {
String title;
String description;
int userId;
...
}
{ "title":"Un titre",
"description":"Un texte",
"userId":100 }
Utiliser JEE (API JAX-RS)
import jakarta.ws.rs.*;
import jakarta.ws.rs.core.*;
@Path("/api")
public class HelloJEERestController {
@POST() @GET() @Path("hello")
public String hello() {
return "Hello";
}
@GET() @Path("hello/{message}")
public String message(@PathParam("message") @DefaultValue("Salut") String m) {
return "Hello " + m;
}
}
L'API JAXB (Java API For XML Binding) est utilisée pour les transformations d'instances java en données JSON/XML et vice-versa.
Utiliser Spring
La partie API-Rest de Spring est une extension de Spring MVC :
import java.util.Date;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/api")
public class HelloRestController {
@GetMapping("/hello")
public String hello() {
return "Hello " + (new Date());
}
}
Le framework Jackson est utilisé pour les transformations d'instances java en données JSON/XML et vice-versa.
Utiliser Spring Data Rest
- Constat : Les échanges de données en entrée et en sortie représentent une grande partie des API-Rest.
- Des actions métier sont également proposées, mais elles sont minoritaires.
-
Spring Data
Rest se propose d'automatiser la construction
d'API-Rest à partir des repositories de
Spring
data.
Les posts de l'utilisateur 100
GET /users/100/posts
Authentification
Les API-Rest sont sans état (comme HTTP). Il faut donc ajouter un système de jeton afin d'identifier un client et assurer la sécurité des échanges.
La solution standard repose sur l'utilisation d'un JWT (Json Web Token). Ce dernier est
- composé de trois parties codées
en base64 et séparées par un point :
<HEADER.PAYLOAD.SIGNATURE>
- L'en-tête est composée de la
spécification de l'algorithme de signature et du type
de jeton :
{ "alg": "HS256", "typ": "JWT" } - La charge utile (Payload) est un
ensemble de couples clé/valeur (appelés des
claims) :
{ "id": "1234", "name": "pierre", "exp": 30 }
- Les claims peuvent être
- réservées : leur objet est défini dans une norme (expiration par exemple)
- publiques : définies librement (mais pas trop longues). Stocker des données est sans doute une mauvaise idée.
- privées : informations spécifiques à une application.
- La signature est fabriquée
avec l'algorithme spécifié, l'en-tête, la charge utile
et une clé secrète connue du serveur. Il existe trois
niveaux de sécurité :
- aucune : le JWT n'est pas signé.
- signé : la signature permet au serveur de valider un JWT qu'il a lui même fabriqué. Il n'y a pas de vérification de l'identité de l'émetteur
- crypté : une clé privée est utilisée pour crypter la charge utile avant sa signature. La clef publique est utilisée pour le décodage. Il est donc possible de vérifier l'émetteur.
Génération d'un JWT
Le jeton est
- fabriqué sur le serveur par une requête d'authentification (GET /login),
- placé dans les en-têtes de la réponse pour transmission au client,
- récupéré par le client et replacé dans les en-têtes des requêtes suivantes,
- vérifié par le serveur pour les entrées qui nécessitent une authentification,
Attention :
- Un JWT est sans état, il ne peut donc pas être désactivé.
- La déconnexion doit entraîner l'oubli du jeton par le client, mais ce dernier est toujours valide (jusqu'à expiration).
- Pour renforcer la sécurité, il faut maintenir, coté serveur une liste noire des jetons désactivés (ou une liste blanche de jetons valides).
- Cette liste noire doit périodiquement être nettoyée des jetons expirés.
Nous allons utiliser le framework jjwt pour utiliser les JWT.
public String createToken(String username) {
Claims claims = Jwts.claims().setSubject(username);
claims.put("auth", "USER,ADMIN");
Date now = new Date();
Date validity = new Date(now.getTime() + validityInMilliseconds);
return Jwts.builder()//
.setClaims(claims)//
.setIssuedAt(now)//
.setExpiration(validity)//
.signWith(SignatureAlgorithm.HS256, secretKey)//
.compact();
}
L'utilisation de HTTPS est conseillé pour la sécurité et la confidentialité des échanges entre client et serveur.
Architectures JWT
- Ajouter une phase d'authentification :
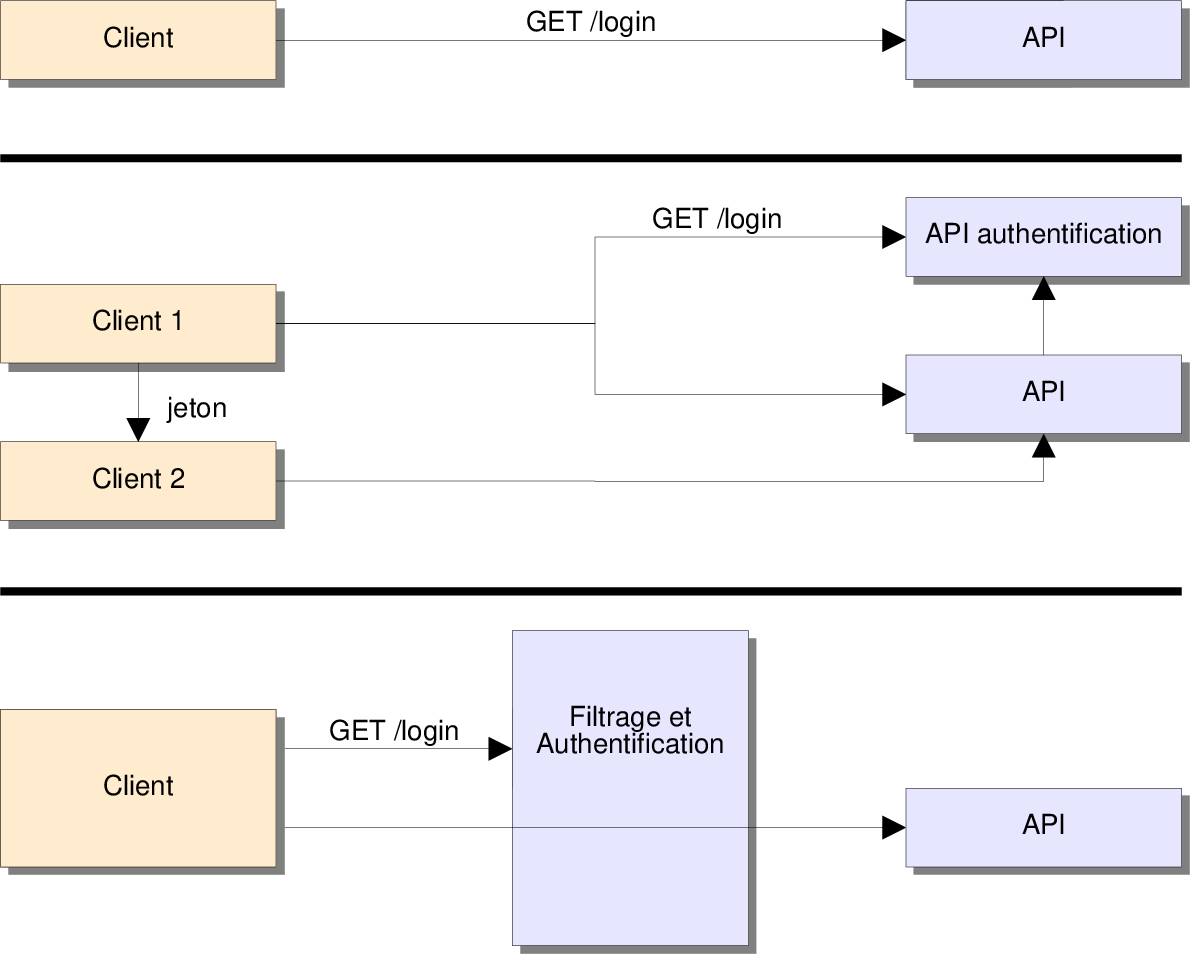
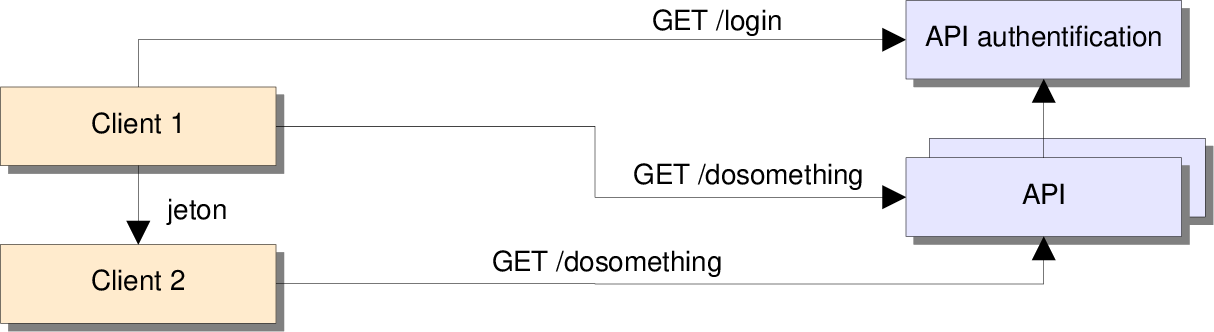
- Isoler une API d'authentification :
Utiliser un API Manager
- Ajouter un API Manager :
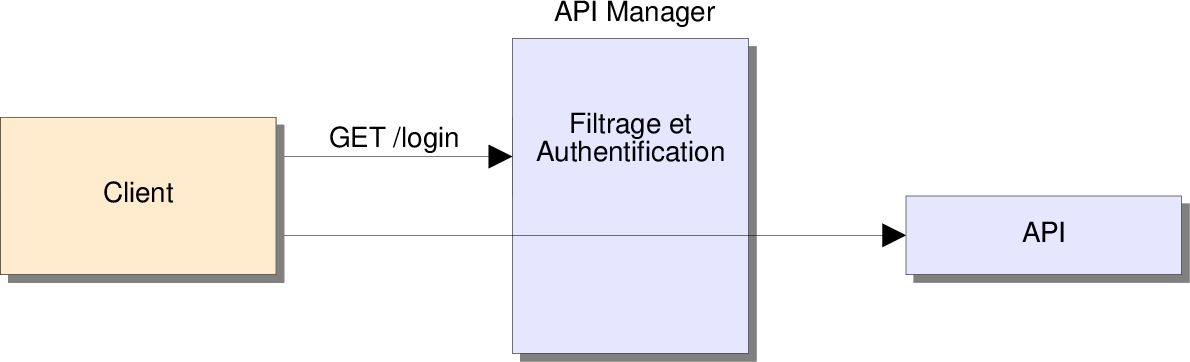
- Il permet
- de gérer l'authentification,
- de rediriger les requêtes,
- de limiter les débits,
- de gérer un cache,
- ...
Services à haut-débit
Les serveurs synchrones utilisent le double modèle du un pour un :
- un thread système par thread java,
- un thread java par requête.
Le serveur est continuellement occupé par le traitement des requêtes et la gestion des threads bloqués par les opérations d'entrés-sorties :
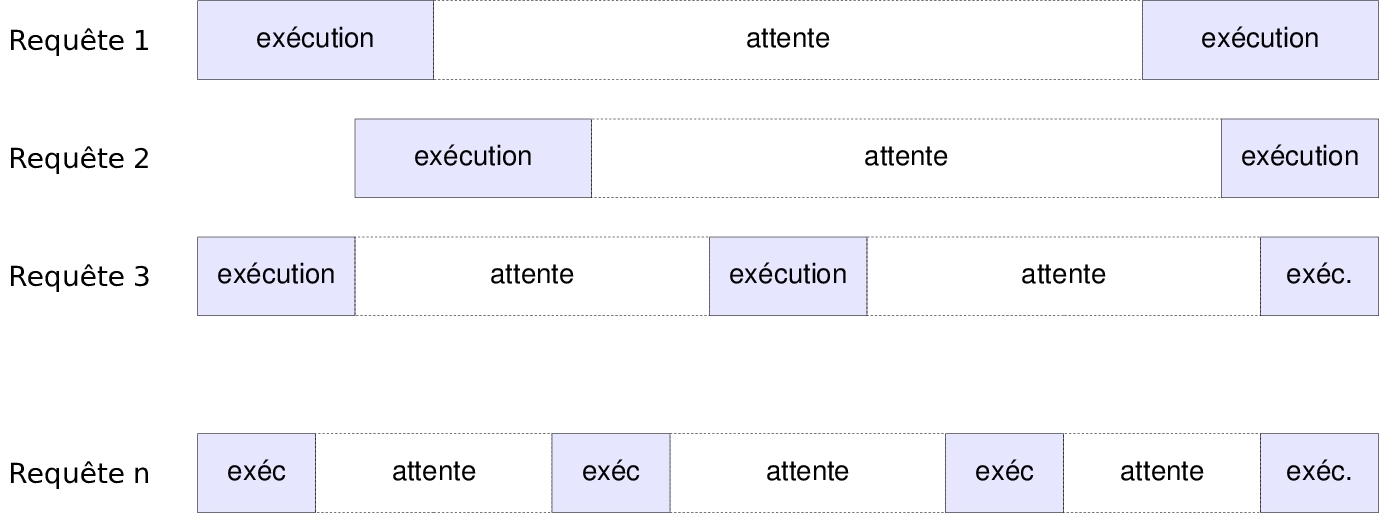
Cette situation entraîne une surcharge système et une mauvaise utilisation des ressources.
Programmation asynchrone
L'idée est de remplacer la programmation synchrone par une programmation asynchrone :
public void aa() { ... }
public void bb() { ... }
public void cc() { ... }
public void job() {
aa();
bb();
cc();
}
public void aa(Runnable next) { ... }
public void bb(Runnable next) { ... }
public void cc() { ... }
public void job() {
aa(() -> {
bb(() -> {
cc();
});
});
}
La distribution de la CPU est effectuée par une boucle d'événements.
public Runnable jobAsynchrone() {
return () -> { aa(() -> { bb(() -> { cc(); }); }); };
}
Si nous avons des données qui circulent :
// seulement producteur
public void aa(Consumer<Data> next) { ... }
// consommateur et producteur
public void bb(Data d, Consumer<Data> next) { ... }
// seulement consommateur
public void cc(Data d) { ... }
public void job() {
aa((data) -> {
bb(data, (dataNext) -> {
cc(dataNext);
});
});
}
Cette approche est appelée programmation réactive : l'appel à bb est une réaction à la publication de données par aa.
Programmation Réactive
Nous allons utiliser le framework reactor pour nous aider dans la mise en place de cette programme réactive :
// consume and produce
public DataB aa(DataA input) { ... }
public DataC bb(DataB input) { ... }
public DataF cc(DataC input) { ... }
public void job() {
Data d1 = new DataA(10);
Data d2 = new DataA(20);
Flux.just(d1, d2)//
.map(this::aa)//
.map(this::bb)//
.map(this::cc)//
.doOnNext(System.out::println)//
.doAfterTerminate(() -> { System.out.println("Done"); })//
.subscribe() ;
}
Les flux peuvent être (a)synchrones, fusionnés, filtrés, transformés.
Utiliser Spring Web-flux
Le framework Spring-flux se propose d'appliquer la programmation réactive à la construite d'API-Web (notamment d'API-REST) :
@GetMapping("/users")
private Flux<User> getAllUsers() {
return userRepository.findAllUsers();
}
@Bean
RouterFunction<ServerResponse> userRoute() {
return route(GET("/users"),
req -> ok().body(
userRepository.findAllUsers(), User.class))
.and(route(GET("/users/{id}"),
req -> ok().body(
userRepository.findUser(req.pathVariable("id")), User.class)));
}
Un client réactif
WebClient client = WebClient.create("http://localhost:8080");
Flux<User> userFlux = client.get()
.uri("/users")
.retrieve()
.bodyToFlux(User.class);
employeeFlux.subscribe(System.out::println);
- La forme fonctionnelle est adaptée à la construction de micro-service simple et facile à concevoir.
- L'utilisation d'une API réactive nécessite une couche de stockage asynchrone. Ce n'est pas le cas de JDBC ou de JPA.
- Il faut éventuellement se tourner vers des systèmes NoSQL qui offrent ce service.
Le retour du un-pour-un avec les micro-threads
A partir de java 21, nous pouvons avoir
- plusieurs micro-threads par thread système (meilleure utilisation de la tranche de temps),
- un ordonnancement fin et léger (réalisé par la JVM) au sein d'un thread système,
- la possibilité de créer plusieurs millions de micro-threads.
> Un processus Une JVM par exemple
est composé de
> plusieurs dizaines de threads Allocation des
eux-mêmes contenant tranches de temps
> plusieurs milliers
de micro-threads exploitation des TT